SQL - Lección 11. Funciones totales, columnas calculadas y vistas
Las funciones totales también se denominan funciones estadísticas, agregadas o de suma. Estas funciones procesan un conjunto de cadenas para contar y devolver un valor único. Sólo hay cinco de estas funciones:- La función AVG() devuelve el valor promedio de una columna.
- La función COUNT() devuelve el número de filas de una columna.
- La función MAX() devuelve el valor más grande de una columna.
- La función MIN() devuelve el valor más pequeño de la columna.
- SUMA() La función devuelve la suma de los valores de la columna.
SELECCIONE MIN(precio), MAX(precio), AVG(precio) DE los precios;

Ahora queremos saber cuánto nos trajo la mercancía el proveedor "House of Printing" (id=2). Hacer una solicitud así no es tan fácil. Pensemos en cómo componerlo:
1. En primer lugar, en la tabla Suministros (entrantes), seleccione los identificadores (id_incoming) de aquellas entregas que fueron realizadas por el proveedor "Print House" (id=2):

2. Ahora desde la tabla Diario de Suministros (magazine_incoming) es necesario seleccionar las mercancías (id_product) y sus cantidades (quantity), que se realizaron en las entregas que se encuentran en el punto 1. Es decir, la consulta del punto 1 queda anidada:

3. Ahora necesitamos agregar a la tabla resultante los precios de los productos encontrados, que se almacenan en la tabla Precios. Es decir, necesitaremos unir las tablas Revista de Suministros (magazine_incoming) y Precios usando la columna id_producto:

4. La tabla resultante claramente carece de la columna Importe, es decir columna calculada. La capacidad de crear este tipo de columnas se proporciona en MySQL. Para hacer esto, solo necesita especificar en la consulta el nombre de la columna calculada y qué se debe calcular. En nuestro ejemplo, dicha columna se llamará summa y calculará el producto de las columnas de cantidad y precio. El nombre de la nueva columna está separado por la palabra AS:
SELECCIONE magazine_incoming.id_product, magazine_incoming.cantidad, precios.precio, magazine_incoming.cantidad*precios.price COMO resumen DE magazine_incoming, precios DONDE magazine_incoming.id_product= precios.id_product AND id_incoming= (SELECCIONE id_incoming DESDE entrante DONDE id_vendor=2);

5. Genial, todo lo que tenemos que hacer es sumar la columna de suma y finalmente averiguar por cuánto nos trajo la mercancía el proveedor “House of Printing”. La sintaxis para utilizar la función SUMA() es la siguiente:
SELECCIONE SUMA (nombre_columna) DESDE nombre_tabla;
Sabemos el nombre de la columna - summa, pero no tenemos el nombre de la tabla, ya que es el resultado de una consulta. ¿Qué hacer? Para tales casos, MySQL tiene Vistas. Una vista es una consulta de selección a la que se le asigna un nombre único y se puede almacenar en una base de datos para su uso posterior.
La sintaxis para crear una vista es la siguiente:
CREAR VISTA nombre_vista AS solicitud;
Guardemos nuestra solicitud como una vista llamada report_vendor:
CREAR VER report_vendor COMO SELECCIONAR magazine_incoming.id_product, magazine_incoming.cantidad, precios.precio, magazine_incoming.cantidad*precios.precio COMO suma DE magazine_incoming, precios DONDE magazine_incoming.id_product= precios.id_product AND id_incoming= (SELECCIONE id_incoming DESDE entrante DONDE id_vendor=2 );
6. Ahora puedes usar la función final SUMA():
SELECCIONE SUMA(summa) DE report_vendor;

Así logramos el resultado, aunque para ello tuvimos que usar consultas anidadas, uniones, columnas calculadas y vistas. Sí, a veces hay que pensar para obtener un resultado, sin ello no se puede llegar a ninguna parte. Pero tocamos dos temas muy importantes: columnas calculadas y vistas. Hablemos de ellos con más detalle.
Campos calculados (columnas)
Usando un ejemplo, hoy analizamos un campo calculado matemáticamente. Aquí me gustaría agregar que puedes usar no solo la operación de multiplicación (*), sino también la resta (-), la suma (+) y la división (/). La sintaxis es la siguiente:SELECCIONE nombre_columna 1, nombre_columna 2, nombre_columna 1 * nombre_columna 2 AS nombre_columna_calculado FROM nombre_tabla;
El segundo matiz es la palabra clave AS, la usamos para establecer el nombre de la columna calculada. De hecho, esta palabra clave se utiliza para establecer alias para cualquier columna. ¿Por qué es esto necesario? Para reducción y legibilidad del código. Por ejemplo, nuestra vista podría verse así:
CREAR VER report_vendor COMO SELECCIONAR A.id_producto, A.cantidad, B.precio, A.cantidad*B.precio COMO suma DE magazine_incoming COMO A, precios COMO B DONDE A.id_product= B.id_product AND id_incoming= (SELECCIONE id_incoming DESDE entrante DONDE id_vendor=2);
Estoy de acuerdo en que esto es mucho más breve y claro.
Representación
Ya hemos visto la sintaxis para crear vistas. Una vez creadas las vistas, se pueden utilizar de la misma manera que las tablas. Es decir, ejecutar consultas sobre ellos, filtrar y ordenar datos y combinar algunas vistas con otras. Por un lado, esta es una forma muy conveniente de almacenar consultas complejas utilizadas con frecuencia (como en nuestro ejemplo).Pero recuerde que las vistas no son tablas, es decir, no almacenan datos, solo los recuperan de otras tablas. Por lo tanto, en primer lugar, cuando los datos de las tablas cambian, los resultados de la presentación también cambiarán. Y en segundo lugar, cuando se realiza una solicitud a una vista, se buscan los datos requeridos, es decir, se reduce el rendimiento del DBMS. Por tanto, no debes abusar de ellos.
Describe el uso de operadores aritméticos y la construcción de columnas calculadas. Se consideran las funciones finales (agregadas) COUNT, SUM, AVG, MAX, MIN. Proporciona un ejemplo del uso del operador GROUP BY para agrupar consultas de selección de datos. Describe el uso de la cláusula HAVING.Construyendo campos calculados
En general, para crear campo calculado (derivado) la lista SELECT debe contener alguna expresión SQL. Estas expresiones utilizan las operaciones aritméticas de suma, resta, multiplicación y división, así como funciones SQL integradas. Puede especificar el nombre de cualquier columna (campo) de una tabla o consulta, pero solo use el nombre de la columna de la tabla o consulta que aparece en la lista de cláusulas FROM de la declaración correspondiente. Al construir expresiones complejas, es posible que se necesiten paréntesis.
Los estándares SQL le permiten especificar explícitamente los nombres de las columnas de la tabla resultante, para las cuales se utiliza la cláusula AS.
SELECCIONE Producto.Nombre, Producto.Precio, Oferta.Cantidad, Producto.Precio*Oferta.Cantidad COMO Costo DEL Producto INNER JOIN Oferta EN Producto.ProductCode=Oferta.ProductCode Ejemplo 6.1. Cálculo del coste total de cada transacción.
Ejemplo 6.2. Obtenga un listado de empresas indicando los apellidos e iniciales de los clientes.
SELECCIONE Empresa, Apellido+""+ Izquierda(Nombre,1)+"."+Izquierda(Segundo Nombre,1)+"."COMO Nombre Completo DEL Cliente Ejemplo 6.2. Obtención de un listado de empresas indicando apellido e iniciales de los clientes.
La solicitud utiliza la función Izquierda incorporada, que en este caso le permite cortar un carácter desde la izquierda en una variable de texto.
Ejemplo 6.3. Obtenga una lista de productos indicando el año y mes de venta.
SELECCIONE Producto.Nombre, Año(Transacción.Fecha) COMO Año, Mes(Transacción.Fecha) COMO Mes DEL Producto INNER JOIN Transacción EN Producto.ProductCode=Transacción.ProductCode Ejemplo 6.3. Recibir un listado de productos indicando el año y mes de venta.
La consulta utiliza las funciones integradas Año y Mes para extraer el año y el mes de una fecha.
Usar funciones de resumen
Mediante el uso funciones finales (agregadas) dentro de la consulta SQL, puede obtener una cantidad de información estadística general sobre el conjunto de valores seleccionados del conjunto de salida.
El usuario tiene acceso a los siguientes contenidos básicos funciones finales:
- Recuento (Expresión): determina el número de registros en el conjunto de resultados de la consulta SQL;
- Min/Max (Expresión): determina el más pequeño y el más grande del conjunto de valores en un determinado campo de solicitud;
- Promedio (Expresión): esta función le permite calcular el promedio de un conjunto de valores almacenados en un campo específico de registros seleccionados por una consulta. Es una media aritmética, es decir la suma de valores dividida por su número.
- Suma (Expresión): Calcula la suma del conjunto de valores contenidos en un campo específico de los registros seleccionados por la consulta.
La mayoría de las veces, los nombres de las columnas se utilizan como expresiones. La expresión también se puede calcular utilizando los valores de varias tablas.
Todas estas funciones operan con valores en una sola columna de una tabla o en una expresión aritmética y devuelven un solo valor. Las funciones COUNT , MIN y MAX se aplican a campos numéricos y no numéricos, mientras que las funciones SUM y AVG solo se pueden usar para campos numéricos, con la excepción de COUNT(*) . Al calcular los resultados de cualquier función, primero se eliminan todos los valores nulos y luego la operación requerida se aplica solo a los valores de columna específicos restantes. La opción COUNT(*) es un caso de uso especial de la función COUNT; su propósito es contar todas las filas de la tabla resultante, independientemente de si contiene valores nulos, duplicados o cualquier otro valor.
Si necesita eliminar valores duplicados antes de utilizar una función de resumen, debe anteponer el nombre de la columna en la definición de la función con la palabra clave DISTINCT. No tiene significado para las funciones MIN y MAX, pero su uso puede afectar los resultados de las funciones SUM y AVG, por lo que debes considerar si debería estar presente en cada caso. Además, la palabra clave DISTINCT solo se puede especificar una vez en cualquier consulta.
Es muy importante señalar que funciones finales solo se puede utilizar en una lista en una cláusula SELECT y como parte de una cláusula HAVING. En todos los demás casos esto es inaceptable. Si la lista en la cláusula SELECT contiene funciones finales y el texto de la consulta no contiene una cláusula GROUP BY, que permite combinar datos en grupos, entonces ninguno de los elementos de la lista de la cláusula SELECT puede incluir referencias a campos, excepto en la situación en la que los campos actúan como argumentos. funciones finales.
Ejemplo 6.4. Determine el primer nombre alfabético del producto.
SELECCIONE Min(Producto.Nombre) COMO Min_Name DEL Producto Ejemplo 6.4. Determinación del primer nombre alfabético del producto.
Ejemplo 6.5. Determinar el número de transacciones.
SELECCIONE Recuento(*) COMO Número_de_ofertas DESDE Oferta Ejemplo 6.5. Determinar el número de transacciones.
Ejemplo 6.6. Determine la cantidad total de bienes vendidos.
SELECCIONE Suma (Oferta.Cantidad) COMO Artículo_Cantidad DE Oferta Ejemplo 6.6. Determinación de la cantidad total de bienes vendidos.
Ejemplo 6.7. Determine el precio promedio de los bienes vendidos.
SELECCIONE Promedio(Producto.Precio) COMO Precio_Promedio DEL Producto UNIRSE INTERNO Oferta EN Producto.ProductCode=Deal.ProductCode; Ejemplo 6.7. Determinación del precio medio de los bienes vendidos.
SELECCIONE Suma (Producto.Precio*Transacción.Cantidad) COMO Costo DEL Producto INNER JOIN Transacción EN Producto.ProductCode=Transacción.ProductCode Ejemplo 6.8. Calcular el costo total de los bienes vendidos.
Cláusula GRUPO POR
Las consultas a menudo requieren la generación de subtotales, lo que generalmente se indica con la aparición de la frase "para cada..." en la consulta. Para este propósito se utiliza una cláusula GROUP BY en la declaración SELECT. Una consulta que contiene GROUP BY se denomina consulta de agrupación porque agrupa los datos devueltos por la operación SELECT y luego crea una única fila de resumen para cada grupo individual. El estándar SQL requiere que la cláusula SELECT y la cláusula GROUP BY estén estrechamente relacionadas. Cuando una instrucción SELECT contiene una cláusula GROUP BY, cada elemento de la lista en la cláusula SELECT debe tener un valor único para todo el grupo. Además, la cláusula SELECT sólo puede incluir los siguientes tipos de elementos: nombres de campos, funciones finales, constantes y expresiones que incluyen combinaciones de los elementos enumerados anteriormente.
Todos los nombres de campo enumerados en la cláusula SELECT también deben aparecer en la cláusula GROUP BY, a menos que el nombre de la columna se use en función final. La regla inversa no es cierta: la cláusula GROUP BY puede contener nombres de columnas que no están en la lista de la cláusula SELECT.
Si se utiliza una cláusula WHERE junto con GROUP BY, se procesa primero y solo se agrupan aquellas filas que satisfacen la condición de búsqueda.
El estándar SQL especifica que al agrupar, todos los valores faltantes se tratan como iguales. Si dos filas de la tabla en la misma columna de agrupación contienen un valor NULL y valores idénticos en todas las demás columnas de agrupación no nulas, se colocan en el mismo grupo.
Ejemplo 6.9. Calcular el volumen medio de compras realizadas por cada cliente.
SELECCIONE Cliente.Apellido, Promedio(Transacción.Cantidad) COMO Cantidad_Promedio DESDE Cliente INNER JOIN Comercio EN Cliente.ClienteCode=Transacción.ClienteCode GRUPO POR Cliente.Apellido Ejemplo 6.9. Calcular el volumen medio de compras realizadas por cada cliente.
La frase "cada cliente" se refleja en la consulta SQL en forma de oración. GRUPO POR Cliente.Apellido.
Ejemplo 6.10. Determine a cuánto se vendió cada producto.
SELECCIONE Producto.Nombre, Suma(Producto.Precio*Transacción.Cantidad) COMO Costo DEL Producto INNER JOIN Oferta EN Producto.ProductCode=Transacción.ProductCode GRUPO POR Producto.Nombre Ejemplo 6.10. Determinación del importe por el que se vendió cada producto.
SELECCIONE Client.Company, Count(Transaction.TransactionCode) COMO Number_of_transactions FROM Client INNER JOIN Transaction ON Client.ClientCode=Transaction.ClientCode GRUPO POR Client.Company Ejemplo 6.11. Contando el número de transacciones realizadas por cada empresa.
SELECCIONE Cliente.Empresa, Suma(Transacción.Cantidad) COMO Cantidad_Total, Suma(Producto.Precio*Transacción.Cantidad) COMO Costo DESDE Producto INNER JOIN (Cliente INNER JOIN Transacción ON Cliente.ClienteCode=Transacción.ClienteCode) ON Producto.ProductCode=Transacción .Código de Producto GRUPO POR Cliente.Empresa Ejemplo 6.12. Cálculo de la cantidad total de bienes adquiridos por cada empresa y su coste.
Ejemplo 6.13. Determine el costo total de cada producto para cada mes.
SELECCIONE Producto.Nombre, Mes(Transacción.Fecha) COMO Mes, Suma(Producto.Precio*Transacción.Cantidad) COMO Costo DEL Producto INNER JOIN Transacción EN Producto.ProductCode=Transacción.ProductCode GRUPO POR Producto.Nombre, Mes(Transacción.Fecha ) Ejemplo 6.13. Determinación del costo total de cada producto para cada mes.
Ejemplo 6.14. Determine el costo total de cada producto de primera clase para cada mes.
SELECCIONE Producto.Nombre, Mes(Transacción.Fecha) COMO Mes, Suma(Producto.Precio*Transacción.Cantidad) COMO Costo DEL Producto INNER JOIN Transacción EN Producto.ProductCode=Transacción.ProductCode DONDE Producto.Grade="Primer" GRUPO POR Producto .Nombre, Mes(Transacción.Fecha) Ejemplo 6.14. Determinación del costo total de cada producto de primera para cada mes.
TENER oferta
Usando HAVING, se reflejan todos los bloques de datos previamente agrupados usando GROUP BY que satisfacen las condiciones especificadas en HAVING. Esta es una opción adicional para "filtrar" el conjunto de salida.
Las condiciones en TENER son diferentes de las condiciones en DONDE:
- HAVING excluye grupos con resultados de valor agregado del conjunto de datos resultante;
- DONDE excluye del cálculo de valores agregados por agrupación los registros que no cumplen la condición;
- Las funciones agregadas no se pueden especificar en la condición de búsqueda WHERE.
Ejemplo 6.15. Identificar empresas cuyo número total de transacciones supere las tres.
SELECCIONE Client.Company, Count(Trade.Quantity) COMO Número_de_ofertas FROM Client INNER JOIN Trade ON Client.ClientCode=Transaction.ClientCode GRUPO POR Client.Company TENIENDO Count(Transaction.Quantity)>3 Ejemplo 6.15. Identificación de empresas cuyo número total de transacciones superó las tres.
Ejemplo 6.16. Muestre una lista de productos vendidos por más de 10.000 rublos.
SELECCIONE Producto.Nombre, Suma(Producto.Precio*Oferta.Cantidad) COMO Costo DEL Producto INNER JOIN Oferta EN Producto.ProductCode=Transacción.ProductCode GRUPO POR Producto.Nombre TENER Suma(Producto.Precio*Oferta.Cantidad)>10000 Ejemplo 6.16. Mostrando una lista de productos vendidos por más de 10.000 rublos.
Ejemplo 6.17. Muestra una lista de productos vendidos por más de 10.000 sin especificar el importe.
SELECCIONE Producto.Nombre DEL Producto INNER JOIN Oferta EN Producto.ProductCode=Oferta.ProductCode GRUPO POR Producto.Nombre TENER Suma(Producto.Precio*Transacción.Cantidad)>10000 Ejemplo 6.17. Muestra una lista de productos vendidos por más de 10.000 sin especificar el importe.
Esta es otra tarea común. El principio básico es acumular los valores de un atributo (el elemento agregado) en función de un orden por otro atributo o atributos (el elemento de orden), posiblemente con secciones de fila definidas en función de otro atributo o atributos más (el elemento de partición). . Hay muchos ejemplos en la vida de cálculo de totales acumulados, como calcular saldos de cuentas bancarias, rastrear la disponibilidad de bienes en un almacén o las cifras de ventas actuales, etc.
Antes de SQL Server 2012, las soluciones basadas en conjuntos utilizadas para calcular los totales acumulados consumían muchísimos recursos. Por eso, la gente tendía a recurrir a soluciones iterativas, que eran lentas, pero aún más rápidas que las soluciones basadas en conjuntos en algunas situaciones. Con soporte ampliado para funciones de ventana en SQL Server 2012, los totales acumulados se pueden calcular utilizando un código simple basado en conjuntos que funciona mucho mejor que las soluciones anteriores basadas en T-SQL, tanto basadas en conjuntos como iterativas. Podría mostrar la nueva solución y pasar a la siguiente sección; pero para ayudarlo a comprender realmente el alcance del cambio, describiré las formas antiguas y compararé su desempeño con el nuevo enfoque. Naturalmente, usted es libre de leer sólo la primera parte, que describe el nuevo enfoque, y omitir el resto del artículo.
Usaré saldos de cuentas para demostrar diferentes soluciones. Aquí está el código que crea y completa la tabla Transacciones con una pequeña cantidad de datos de prueba:
NO CONFIGURAR CUENTA EN; UTILICE TSQL2012; SI OBJECT_ID("dbo.Transactions", "U") NO ES NULL DROP TABLE dbo.Transactions; CREAR TABLA dbo.Transactions (actid INT NOT NULL, -- columna de partición tranid INT NOT NULL, -- columna de pedido val MONEY NOT NULL, -- medida CONSTRAINT PK_Transactions PRIMARY KEY(actid, tranid)); GO: pequeño conjunto de datos de prueba INSERTAR EN dbo.Transactions(actid, tranid, val) VALORES (1, 1, 4.00), (1, 2, -2.00), (1, 3, 5.00), (1, 4, 2,00), (1, 5, 1,00), (1, 6, 3,00), (1, 7, -4,00), (1, 8, -1,00), (1, 9, -2,00), (1, 10 , -3,00), (2, 1, 2,00), (2, 2, 1,00), (2, 3, 5,00), (2, 4, 1,00), (2, 5, -5,00), (2, 6 , 4,00), (2, 7, 2,00), (2, 8, -4,00), (2, 9, -5,00), (2, 10, 4,00), (3, 1, -3,00), (3, 2, 3,00), (3, 3, -2,00), (3, 4, 1,00), (3, 5, 4,00), (3, 6, -1,00), (3, 7, 5,00), (3, 8, 3,00), (3, 9, 5,00), (3, 10, -3,00);
Cada fila de la tabla representa una transacción bancaria en una cuenta. Los depósitos se marcan como transacciones con un valor positivo en la columna val y los retiros se marcan como un valor de transacción negativo. Nuestra tarea es calcular el saldo de la cuenta en cada momento acumulando los montos de las transacciones en la fila val, ordenados por la columna tranid, y esto debe hacerse para cada cuenta por separado. El resultado deseado debería verse así:
Para probar ambas soluciones, se necesitan más datos. Esto se puede hacer con una consulta como esta:
DECLARAR @num_partitions COMO INT = 10, @rows_per_partition COMO INT = 10000; TRUNCAR TABLA dbo.Transacciones; INSERTAR EN dbo.Transacciones CON (TABLOCK) (actid, tranid, val) SELECCIONAR NP.n, RPP.n, (ABS(CHECKSUM(NEWID())%2)*2-1) * (1 + ABS(CHECKSUM( NEWID())%5)) FROM dbo.GetNums(1, @num_partitions) COMO NP CROSS JOIN dbo.GetNums(1, @rows_per_partition) COMO RPP;
Puede configurar sus entradas para cambiar la cantidad de secciones (cuentas) y filas (transacciones) en una sección.
Solución basada en conjuntos que utiliza funciones de ventana
Comenzaré con una solución basada en conjuntos que utiliza la función de agregación de ventanas SUM. La definición de ventana aquí es bastante clara: debe seccionar la ventana por actid, organizarla por tranid y usar un filtro para seleccionar las líneas en el marco desde la más inferior (ANTERIOR SIN LÍMITES) hasta la actual. Aquí está la solicitud correspondiente:
SELECCIONE actid, tranid, val, SUM(val) SOBRE(PARTICIÓN POR actid ORDEN POR FILAS tranid ENTRE FILA ANTERIOR Y ACTUAL SIN LÍMITES) COMO saldo DE dbo.Transactions;
Este código no sólo es simple y directo, sino que también es rápido. El plan para esta consulta se muestra en la figura:
La tabla tiene un índice agrupado que cumple con los requisitos de POC y puede ser utilizado por funciones de ventana. Específicamente, la lista de claves de índice se basa en un elemento de partición (actid) seguido de un elemento de orden (tranid), y el índice también incluye todas las demás columnas de la consulta (val) para proporcionar cobertura. El plan contiene un escaneo ordenado, seguido del cálculo del número de línea para necesidades internas y luego el agregado de ventana. Dado que existe un índice POC, el optimizador no necesita agregar un operador de clasificación al plan. Este es un plan muy efectivo. Además, escala linealmente. Más adelante, cuando muestre los resultados de la comparación de rendimiento, verá cuánto más eficaz es este método en comparación con soluciones anteriores.
Antes de SQL Server 2012, se utilizaban subconsultas o uniones. Cuando se utiliza una subconsulta, los totales acumulados se calculan filtrando todas las filas con el mismo valor actid que la fila exterior y un valor tranid que es menor o igual que el valor de la fila exterior. Luego se aplica la agregación a las filas filtradas. Aquí está la solicitud correspondiente:
Se puede implementar un enfoque similar utilizando conexiones. Se utiliza el mismo predicado que en la cláusula WHERE de la subconsulta en la cláusula ON de la unión. En este caso, para la enésima transacción de la misma cuenta A en la instancia designada T1, encontrará N coincidencias en la instancia T2, con números de transacción que van del 1 al N. Como resultado de las coincidencias, las filas en T1 son repetido, por lo que necesita agrupar las filas en todos los elementos de T1 para obtener información sobre la transacción actual y aplicar agregación al atributo val de T2 para calcular el total acumulado. La solicitud completa se parece a esto:
SELECCIONE T1.actid, T1.tranid, T1.val, SUM(T2.val) COMO saldo DE dbo.Transactions COMO T1 ÚNASE a dbo.Transactions COMO T2 EN T2.actid = T1.actid Y T2.tranid<= T1.tranid GROUP BY T1.actid, T1.tranid, T1.val;
La siguiente figura muestra los planes para ambas soluciones:

Tenga en cuenta que en ambos casos, se realiza un análisis completo del índice agrupado en la instancia T1. Luego, para cada fila del plan, hay una operación de búsqueda en el índice del comienzo de la sección de cuenta corriente en la página final del índice, que lee todas las transacciones en las que T2.tranid es menor o igual que T1. tranid. El punto donde se produce la agregación de filas es ligeramente diferente en los planes, pero el número de filas leídas es el mismo.
Para comprender cuántas filas se están analizando, debe considerar la cantidad de elementos de datos. Sea p el número de secciones (cuentas) y r el número de filas de la sección (transacción). Entonces, el número de filas de la tabla es aproximadamente igual a p*r, si asumimos que las transacciones se distribuyen uniformemente entre las cuentas. Entonces, el escaneo anterior cubre filas p*r. Pero lo que más nos interesa es lo que sucede en el iterador de Nested Loops.
En cada sección, el plan prevé la lectura de 1 + 2 + ... + r filas, que en total es (r + r*2) / 2. El número total de filas procesadas en los planes es p*r + p* (r + r2) / 2. Esto significa que el número de operaciones en el plan aumenta al cuadrado al aumentar el tamaño de la sección, es decir, si aumenta el tamaño de la sección f veces, la cantidad de trabajo aumentará aproximadamente f 2 veces. Esto es malo. Por ejemplo, 100 líneas corresponden a 10 mil líneas y mil líneas corresponden a un millón, etc. En pocas palabras, esto conduce a una desaceleración significativa en la ejecución de consultas con un tamaño de sección bastante grande, porque la función cuadrática crece muy rápidamente. Estas soluciones funcionan satisfactoriamente con varias docenas de líneas por sección, pero no más.
Soluciones de cursor
Las soluciones basadas en cursores se implementan de frente. Se declara un cursor en función de una consulta que ordena los datos por actid y tranid. Después de esto, se realiza un paso iterativo por los registros del cursor. Cuando se detecta una nueva cuenta, se restablece la variable que contiene el agregado. En cada iteración, el monto de la nueva transacción se agrega a la variable, después de lo cual la fila se almacena en una variable de tabla con información sobre la transacción actual más el valor actual del total acumulado. Después de un paso iterativo, se devuelve el resultado de la variable de la tabla. Aquí está el código para la solución completa:
DECLARAR @Resultado COMO TABLA (actid INT, tranid INT, val DINERO, saldo DINERO); DECLARAR @actid COMO INT, @prvactid COMO INT, @tranid COMO INT, @val COMO DINERO, @balance COMO DINERO; DECLARAR C CURSOR FAST_FORWARD PARA SELECCIONAR actid, tranid, val DE dbo.Transactions ORDEN POR actid, tranid; ABRIR C BUSCAR SIGUIENTE DE C EN @actid, @tranid, @val; SELECCIONE @prvactid = @actid, @balance = 0; MIENTRAS @@fetch_status = 0 COMENZAR SI @actid<>@prvactid SELECCIONAR @prvactid = @actid, @balance = 0; SET @saldo = @saldo + @val; INSERTAR EN @Result VALUES(@actid, @tranid, @val, @balance); BUSCAR SIGUIENTE DE C A @actid, @tranid, @val; FIN CIERRE C; DESASIGNAR C; SELECCIONAR * DE @Resultado;
El plan de consulta utilizando un cursor se muestra en la figura:

Este plan escala linealmente porque los datos del índice se escanean solo una vez en un orden específico. Además, cada operación para recuperar una fila de un cursor tiene aproximadamente el mismo costo por fila. Si tomamos la carga creada al procesar una línea del cursor como igual a g, el costo de esta solución se puede estimar como p*r + p*r*g (como recordará, p es el número de secciones y r es el número de filas en la sección). Entonces, si aumenta el número de filas por sección f veces, la carga en el sistema será p*r*f + p*r*f*g, es decir, crecerá linealmente. El costo de procesamiento por fila es alto, pero debido a la naturaleza lineal del escalado, a partir de un cierto tamaño de partición, esta solución exhibirá una mejor escalabilidad que las soluciones basadas en consultas anidadas y uniones debido al escalamiento cuadrático de estas soluciones. Las mediciones de rendimiento que he realizado muestran que el número en el que la solución del cursor es más rápida es de unos cientos de filas por partición.
A pesar de los beneficios de rendimiento que ofrecen las soluciones basadas en cursores, generalmente deben evitarse porque no son relacionales.
Soluciones basadas en CLR
Una posible solución basada en CLR (Tiempo de ejecución de lenguaje común) es esencialmente una forma de solución usando un cursor. La diferencia es que en lugar de utilizar un cursor T-SQL, que desperdicia muchos recursos para obtener la siguiente fila e iterar, se utilizan .NET SQLDataReader y .NET iteraciones, que son mucho más rápidas. Una de las características de CLR que hace que esta opción sea más rápida es que la fila resultante no es necesaria en una tabla temporal: los resultados se envían directamente al proceso de llamada. La lógica de una solución basada en CLR es similar a la de una solución de cursor y T-SQL. Aquí está el código C# que define el procedimiento almacenado de resolución:
Usando el Sistema; usando System.Data; usando System.Data.SqlClient; usando System.Data.SqlTypes; utilizando Microsoft.SqlServer.Server; clase parcial pública StoredProcedures ( public static void AccountBalances() ( usando (SqlConnection conn = new SqlConnection("conexión de contexto = true;")) ( SqlCommand comm = new SqlCommand(); comm.Connection = conn; comm.CommandText = @" " + "SELECCIONAR actid, tranid, val " + "DESDE dbo.Transactions " + "ORDENAR POR actid, tranid;"; columnas SqlMetaData = nuevo SqlMetaData; columnas = nuevo SqlMetaData("actid", SqlDbType.Int); columnas = nuevo SqlMetaData("tranid", SqlDbType.Int); columnas = nuevo SqlMetaData("val", SqlDbType.Money); columnas = nuevo SqlMetaData("balance", SqlDbType.Money); registro SqlDataRecord = nuevo SqlDataRecord(columnas); SqlContext. Pipe.SendResultsStart(registro); conn.Open(); lector SqlDataReader = comm.ExecuteReader(); SqlInt32 prvactid = 0; saldo de SqlMoney = 0; while (reader.Read()) ( SqlInt32 actid = lector.GetSqlInt32(0) ; SqlMoney val = lector.GetSqlMoney(2); if (actid == prvactid) (saldo += val;) else (saldo = val;) prvactid = actid; record.SetSqlInt32(0, lector.GetSqlInt32(0)); record.SetSqlInt32(1, lector.GetSqlInt32(1)); registro.SetSqlMoney(2, val); record.SetSqlMoney(3, saldo); SqlContext.Pipe.SendResultsRow(registro); ) SqlContext.Pipe.SendResultsEnd(); ) ) )
Para poder ejecutar este procedimiento almacenado en SQL Server, primero debe crear un ensamblado llamado AccountBalances basado en este código e implementarlo en la base de datos TSQL2012. Si no está familiarizado con la implementación de ensamblados en SQL Server, es posible que desee leer la sección Procedimientos almacenados y CLR en el artículo Procedimientos almacenados.
Si nombró el ensamblado AccountBalances y la ruta al archivo del ensamblado es "C:\Projects\AccountBalances\bin\Debug\AccountBalances.dll", puede cargar el ensamblado en la base de datos y registrar el procedimiento almacenado con el siguiente código:
CREAR ENSAMBLAJE AccountBalances DESDE "C:\Projects\AccountBalances\bin\Debug\AccountBalances.dll"; IR A CREAR PROCEDIMIENTO dbo.AccountBalances COMO NOMBRE EXTERNO AccountBalances.StoredProcedures.AccountBalances;
Después de implementar el ensamblado y registrar el procedimiento, puede ejecutarlo con el siguiente código:
EXEC dbo.AccountBalances;
Como dije, SQLDataReader es solo otra forma de cursor, pero esta versión tiene un costo significativamente menor para leer filas que usar un cursor tradicional en T-SQL. Las iteraciones también son mucho más rápidas en .NET que en T-SQL. Por tanto, las soluciones basadas en CLR también escalan linealmente. Las pruebas han demostrado que el rendimiento de esta solución es mayor que el rendimiento de las soluciones que utilizan subconsultas y uniones cuando el número de filas en una sección supera las 15.
Cuando termine, debe ejecutar el siguiente código de limpieza:
PROCEDIMIENTO DE BAJA dbo.AccountBalances; ASAMBLEA DE GOTASaldos de cuentas;
Iteraciones anidadas
Hasta este punto, he mostrado soluciones iterativas y basadas en conjuntos. La siguiente solución se basa en iteraciones anidadas, que es un híbrido de enfoques iterativos y basados en conjuntos. La idea es copiar primero las filas de la tabla fuente (en nuestro caso, cuentas bancarias) en una tabla temporal junto con un nuevo atributo llamado rownum, que se calcula usando la función ROW_NUMBER. Los números de línea se dividen por actid y se ordenan por tranid, por lo que a la primera transacción en cada cuenta bancaria se le asigna el número 1, a la segunda transacción se le asigna el número 2, y así sucesivamente. Luego se crea un índice agrupado en la tabla temporal con una lista de claves (rownum, actid). Luego se utiliza una expresión CTE recursiva o un bucle especialmente diseñado para procesar una fila por iteración en todas las cuentas. Luego, el total acumulado se calcula sumando el valor asociado con la fila actual con el valor asociado con la fila anterior. Aquí hay una implementación de esta lógica usando un CTE recursivo:
SELECCIONE actid, tranid, val, ROW_NUMBER() SOBRE(PARTICIÓN POR actid ORDEN POR tranid) AS rownum INTO #Transactions FROM dbo.Transactions; CREAR ÍNDICE AGRUPADO ÚNICO idx_rownum_actid ON #Transactions(rownum, actid); CON C COMO (SELECCIONE 1 COMO rownum, actid, tranid, val, val COMO sumqty DESDE #Transacciones DONDE rownum = 1 UNION TODO SELECCIONE PRV.rownum + 1, PRV.actid, CUR.tranid, CUR.val, PRV.sumqty + CUR.val FROM C AS PRV JOIN #Transacciones COMO CUR ON CUR.rownum = PRV.rownum + 1 AND CUR.actid = PRV.actid) SELECCIONE actid, tranid, val, sumqty FROM C OPTION (MAXRECURSION 0); DROP TABLE #Transacciones;
Y esta es una implementación que utiliza un bucle explícito:
SELECCIONE ROW_NUMBER() SOBRE(PARTICIÓN POR actid ORDEN POR tranid) COMO rownum, actid, tranid, val, CAST(val AS BIGINT) AS sumqty INTO #Transactions FROM dbo.Transactions; CREAR ÍNDICE AGRUPADO ÚNICO idx_rownum_actid ON #Transactions(rownum, actid); DECLARAR @rownum COMO INT; ESTABLECER @rownum = 1; MIENTRAS 1 = 1 COMENZAR CONFIGURAR @rownum = @rownum + 1; ACTUALIZAR CUR SET sumqty = PRV.sumqty + CUR.val FROM #Transactions AS CUR JOIN #Transactions AS PRV ON CUR.rownum = @rownum AND PRV.rownum = @rownum - 1 AND CUR.actid = PRV.actid; SI @@rowcount = 0 DESCANSO; FIN SELECT actid, tranid, val, sumqty FROM #Transacciones; DROP TABLE #Transacciones;
Esta solución proporciona un buen rendimiento cuando hay una gran cantidad de particiones con una pequeña cantidad de filas por partición. Entonces, el número de iteraciones es pequeño y la mayor parte del trabajo lo realiza la parte de la solución basada en conjuntos, que conecta las filas asociadas con un número de fila con las filas asociadas con el número de fila anterior.
Actualización multilínea con variables.
Se garantiza que los métodos para calcular los totales acumulados mostrados hasta este punto darán el resultado correcto. La técnica descrita en esta sección es controvertida porque se basa en el comportamiento del sistema observado, más que documentado, y también contradice los principios de la relatividad. Su alto atractivo se debe a su alta velocidad de trabajo.
Este método utiliza una declaración ACTUALIZAR con variables. La declaración ACTUALIZAR puede asignar expresiones a variables según el valor de una columna y también puede asignar valores en columnas a una expresión con una variable. La solución comienza creando una tabla temporal llamada Transacciones con los atributos actid, tranid, val y balance y un índice agrupado con una lista de claves (actid, tranid). Luego, la tabla temporal se llena con todas las filas de la base de datos de Transacciones de origen y el valor 0,00 se ingresa en la columna de saldo de todas las filas. Luego se llama a una instrucción UPDATE con las variables asociadas con la tabla temporal para calcular los totales acumulados e insertar el valor calculado en la columna de saldo.
Se utilizan las variables @prevaccount y @prevbalance, y el valor en la columna de saldo se calcula usando la siguiente expresión:
SET @prevbalance = balance = CASO CUANDO actid = @prevaccount ENTONCES @prevbalance + val ELSE val FIN
La expresión CASE verifica si los ID de cuenta actuales y anteriores son los mismos y, si lo son, devuelve la suma de los valores anteriores y actuales en la columna de saldo. Si los ID de cuenta son diferentes, se devuelve el monto de la transacción actual. A continuación, el resultado de la expresión CASE se inserta en la columna de saldo y se asigna a la variable @prevbalance. En una expresión separada, a la variable ©prevaccount se le asigna el ID de la cuenta corriente.
Después de la declaración UPDATE, la solución presenta las filas de la tabla temporal y elimina la última. Aquí está el código para la solución completa:
CREAR TABLA #Transacciones (actid INT, tranid INT, val DINERO, saldo DINERO); CREAR ÍNDICE AGRUPADO idx_actid_tranid EN #Transacciones(actid, tranid); INSERTAR EN #Transacciones CON (TABLOQUE) (actid, tranid, val, balance) SELECCIONAR actid, tranid, val, 0.00 FROM dbo.Transactions ORDENAR POR actid, tranid; DECLARAR @prevaccount COMO INT, @prevbalance COMO DINERO; ACTUALIZAR #Transacciones SET @prevbalance = saldo = CASO CUANDO actid = @prevaccount ENTONCES @prevbalance + val ELSE val FIN, @prevaccount = actid DESDE #Transacciones CON(INDEX(1), TABLOCKX) OPCIÓN (MAXDOP 1); SELECCIONAR * DE #Transacciones; DROP TABLE #Transacciones;
El esquema de esta solución se muestra en la siguiente figura. La primera parte está representada por la declaración INSERT, la segunda por UPDATE y la tercera por la declaración SELECT:

Esta solución supone que la optimización de la ejecución de UPDATE siempre realizará un escaneo ordenado del índice agrupado y la solución proporciona una serie de sugerencias para evitar circunstancias que podrían impedir esto, como la concurrencia. El problema es que no existe una garantía oficial de que el optimizador siempre buscará en el orden del índice agrupado. No se puede confiar en el cálculo físico para garantizar que el código sea lógicamente correcto a menos que haya elementos lógicos en el código que, por definición, puedan garantizar ese comportamiento. No existe ninguna característica lógica en este código que pueda garantizar este comportamiento. Naturalmente, la elección de utilizar o no este método recae enteramente en su conciencia. Creo que es irresponsable usarlo, incluso si lo has revisado miles de veces y "todo parece funcionar como debería".
Afortunadamente, SQL Server 2012 hace que esta elección sea prácticamente innecesaria. Cuando tiene una solución extremadamente eficiente que utiliza funciones de agregación en ventanas, no tiene que pensar en otras soluciones.
medición del desempeño
Medí y comparé el rendimiento de varias técnicas. Los resultados se muestran en las siguientes figuras:

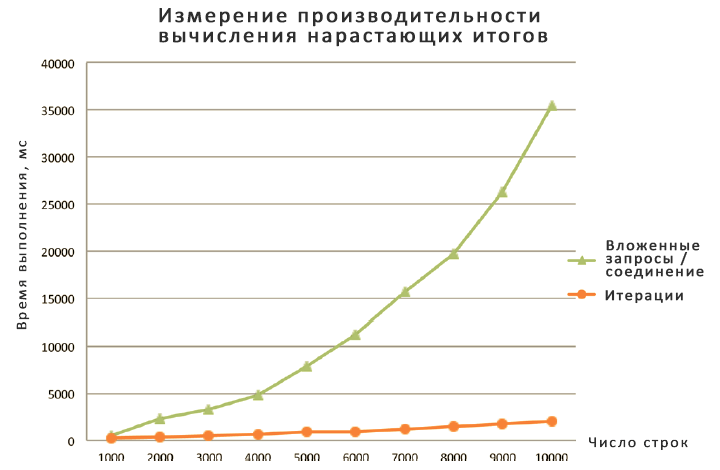
Dividí los resultados en dos gráficos porque el método de subconsulta/unión es mucho más lento que los demás y tuve que usar una escala diferente para ello. En cualquier caso, tenga en cuenta que la mayoría de las soluciones muestran una relación lineal entre la carga de trabajo y el tamaño de la partición, y sólo la subconsulta o solución de unión muestra una relación cuadrática. También queda claro cuánto más eficiente es la nueva solución basada en la función de agregación en ventanas. La solución ACTUALIZAR con variables también es muy rápida, pero por los motivos ya descritos no recomiendo usarla. La solución CLR también es bastante rápida, pero hay que escribir todo ese código .NET e implementar el ensamblado en la base de datos. No importa cómo se mire, una solución basada en kit que utilice unidades de ventana sigue siendo la más preferible.
Aprendamos a resumir. No, estos no son los resultados del estudio de SQL, sino los resultados de los valores de las columnas de las tablas de la base de datos. Las funciones agregadas de SQL operan sobre los valores de una columna para producir un único valor resultante. Las funciones agregadas de SQL más utilizadas son SUM, MIN, MAX, AVG y COUNT. Es necesario distinguir entre dos casos de uso de funciones agregadas. En primer lugar, las funciones agregadas se utilizan por sí solas y devuelven un único valor resultante. En segundo lugar, se utilizan funciones agregadas con la cláusula SQL GROUP BY, es decir, agrupar por campos (columnas) para obtener los valores resultantes en cada grupo. Consideremos primero casos de uso de funciones agregadas sin agrupación.
Función SUMA SQL
La función SQL SUM devuelve la suma de los valores en una columna de la tabla de la base de datos. Sólo se puede aplicar a columnas cuyos valores sean números. Las consultas SQL para obtener la suma resultante comienzan así:
SELECCIONE SUMA (NOMBRE_COLUMNA)...
Esta expresión va seguida de FROM (TABLE_NAME) y luego se puede especificar una condición utilizando la cláusula WHERE. Además, el nombre de la columna puede ir precedido de DISTINCT, lo que significa que solo se contarán los valores únicos. De forma predeterminada, se tienen en cuenta todos los valores (para esto, puede especificar específicamente no DISTINCT, sino TODOS, pero no se requiere la palabra TODOS).
Si desea ejecutar consultas de bases de datos de esta lección en MS SQL Server, pero este DBMS no está instalado en su computadora, puede instalarlo siguiendo las instrucciones en este enlace. .
Primero trabajaremos con la base de datos de la empresa: Empresa1. El script para crear esta base de datos, sus tablas y llenar las tablas con datos se encuentra en el archivo en este enlace .
Ejemplo 1. Existe una base de datos de la empresa con datos sobre sus divisiones y empleados. La tabla Personal también tiene una columna con datos sobre los salarios de los empleados. La selección de la tabla se ve así (para ampliar la imagen, haga clic en ella con el botón izquierdo del mouse):
Para obtener la suma de todos los salarios, utilizamos la siguiente consulta (en MS SQL Server - con la construcción anterior USE empresa1;):
SELECCIONE SUMA (Salario) DEL Personal
Esta consulta devolverá el valor 287664,63.
Y ahora . En los ejercicios ya empezamos a complicar las tareas, acercándolas a las que encontramos en la práctica.
Función mínima de SQL
La función SQL MIN también opera en columnas cuyos valores son números y devuelve el mínimo de todos los valores de la columna. Esta función tiene una sintaxis similar a la de la función SUMA.
Ejemplo 3. La base de datos y la tabla son las mismas que en el ejemplo 1.
Necesitamos averiguar el salario mínimo de los empleados del departamento número 42. Para hacer esto, escriba la siguiente consulta (en MS SQL Server, con el prefijo USE empresa1;):
La consulta devolverá el valor 10505,90.
Y otra vez ejercicio para la auto-solución. En este y algunos otros ejercicios, necesitará no solo la tabla Staff, sino también la tabla Org, que contiene datos sobre las divisiones de la empresa:

Ejemplo 4. La tabla Org se agrega a la tabla Staff y contiene datos sobre los departamentos de la empresa. Imprima el número mínimo de años trabajados por un empleado en un departamento ubicado en Boston.
Función SQL MAX
La función SQL MAX funciona de manera similar y tiene una sintaxis similar, que se usa cuando necesita determinar el valor máximo entre todos los valores de una columna.
Ejemplo 5.
Necesitamos averiguar el salario máximo de los empleados en el departamento número 42. Para hacer esto, escriba la siguiente consulta (en MS SQL Server - con el prefijo USE empresa1;):
La consulta devolverá el valor 18352,80.
Es la hora ejercicios para solución independiente.
Ejemplo 6. Volvemos a trabajar con dos tablas: Staff y Org. Muestra el nombre del departamento y el valor máximo de la comisión que recibe un empleado del departamento perteneciente al grupo de departamentos (División) Este. Usar JOIN (unir mesas) .
Función SQL AVG
Lo que se afirma con respecto a la sintaxis de las funciones anteriores descritas también es válido para la función SQL AVG. Esta función devuelve el promedio de todos los valores de una columna.
Ejemplo 7. La base de datos y la tabla son las mismas que en los ejemplos anteriores.
Supongamos que desea conocer la duración promedio de servicio de los empleados en el departamento número 42. Para hacer esto, escriba la siguiente consulta (en MS SQL Server, con el USE de construcción anterior empresa1;):
El resultado será 6,33.
Ejemplo 8. Trabajamos con una mesa: el personal. Muestra el salario promedio de los empleados con 4 a 6 años de experiencia.
Función CUENTA SQL
La función SQL COUNT devuelve el número de registros en una tabla de base de datos. Si especifica SELECT COUNT(COLUMN_NAME) ... en la consulta, el resultado será el número de registros sin tener en cuenta aquellos registros en los que el valor de la columna sea NULL (indefinido). Si utiliza un asterisco como argumento e inicia una consulta SELECT COUNT(*) ..., el resultado será el número de todos los registros (filas) de la tabla.
Ejemplo 9. La base de datos y la tabla son las mismas que en los ejemplos anteriores.
Quiere saber el número de todos los empleados que reciben comisiones. La siguiente consulta devolverá el número de empleados cuyos valores de la columna Comm no son NULL (en MS SQL Server, con el prefijo USE empresa1;):
SELECCIONAR RECUENTO (Comunicación) DEL Personal
El resultado será 11.
Ejemplo 10. La base de datos y la tabla son las mismas que en los ejemplos anteriores.
Si desea conocer el número total de registros en la tabla, utilice una consulta con un asterisco como argumento para la función CONTAR (en MS SQL Server, con la construcción anterior USE empresa1;):
SELECCIONAR RECUENTO (*) DEL Personal
El resultado será 17.
En el proximo ejercicio para la solución independiente necesitarás utilizar una subconsulta.
Ejemplo 11. Trabajamos con una mesa: el personal. Muestra el número de empleados en el departamento de planificación (Plains).
Funciones agregadas con SQL GROUP BY
Ahora veamos el uso de funciones agregadas junto con la declaración SQL GROUP BY. La instrucción SQL GROUP BY se utiliza para agrupar valores de resultados por columnas en una tabla de base de datos. El sitio web tiene una lección dedicada por separado a este operador .
Trabajaremos con la base de datos "Ads Portal 1". El script para crear esta base de datos, su tabla y completar la tabla de datos se encuentra en el archivo en este enlace .
Ejemplo 12. Entonces, existe una base de datos del portal de publicidad. Tiene una tabla de anuncios que contiene datos sobre los anuncios enviados durante la semana. La columna Categoría contiene datos sobre categorías de anuncios grandes (por ejemplo, Bienes raíces) y la columna Partes contiene datos sobre partes más pequeñas incluidas en las categorías (por ejemplo, las partes Apartamentos y Casas de verano son partes de la categoría Bienes raíces). La columna Unidades contiene datos sobre la cantidad de anuncios enviados y la columna Dinero contiene datos sobre la cantidad de dinero recibida por enviar anuncios.
| Categoría | Parte | Unidades | Dinero |
| Transporte | Carros | 110 | 17600 |
| Bienes raíces | Apartamentos | 89 | 18690 |
| Bienes raíces | dachas | 57 | 11970 |
| Transporte | motocicletas | 131 | 20960 |
| Materiales de construcción | tableros | 68 | 7140 |
| Ingenieria Eléctrica | Televisores | 127 | 8255 |
| Ingenieria Eléctrica | Refrigeradores | 137 | 8905 |
| Materiales de construcción | Regímenes | 112 | 11760 |
| Ocio | Libros | 96 | 6240 |
| Bienes raíces | En casa | 47 | 9870 |
| Ocio | Música | 117 | 7605 |
| Ocio | Juegos | 41 | 2665 |
Utilizando la instrucción SQL GROUP BY, encuentre la cantidad de dinero que se gana al publicar anuncios en cada categoría. Escribimos la siguiente consulta (en MS SQL Server - con la construcción anterior USE adportal1;):
SELECCIONE Categoría, SUMA (Dinero) COMO Dinero DEL GRUPO DE ANUNCIOS POR Categoría
Ejemplo 13. La base de datos y la tabla son las mismas que en el ejemplo anterior.
Usando la instrucción SQL GROUP BY, descubra qué parte de cada categoría tenía la mayor cantidad de listados. Escribimos la siguiente consulta (en MS SQL Server - con la construcción anterior USE adportal1;):
SELECCIONE Categoría, Parte, MAX (Unidades) COMO Máximo DEL GRUPO DE ANUNCIOS POR Categoría
El resultado será la siguiente tabla:
Los valores totales e individuales se pueden obtener en una tabla. combinar resultados de consultas utilizando el operador UNION .
Bases de datos relacionales y lenguaje SQL
¿Cómo puedo saber la cantidad de modelos de PC producidos por un proveedor en particular? ¿Cómo determinar el precio medio de ordenadores con las mismas características técnicas? Estas y muchas otras preguntas relacionadas con cierta información estadística se pueden responder utilizando funciones finales (agregadas). El estándar proporciona las siguientes funciones agregadas:
Todas estas funciones devuelven un único valor. Al mismo tiempo, las funciones CUENTA, MÍNIMO Y MÁXIMO aplicable a cualquier tipo de datos, mientras SUMA Y AVG se utilizan sólo para campos numéricos. Diferencia entre función CONTAR(*) Y CONTAR(<имя поля>) es que el segundo no tiene en cuenta los valores NULL al calcular.
Ejemplo. Encuentre el precio mínimo y máximo para computadoras personales:
Ejemplo. Encuentre la cantidad disponible de computadoras producidas por el fabricante A:
Ejemplo. Si estamos interesados en la cantidad de modelos diferentes producidos por el fabricante A, entonces la consulta se puede formular de la siguiente manera (utilizando el hecho de que en la tabla Producto cada modelo se registra una vez):
Ejemplo. Encuentre la cantidad de modelos diferentes disponibles producidos por el fabricante A. La consulta es similar a la anterior, en la que se requería determinar la cantidad total de modelos producidos por el fabricante A. Aquí también necesita encontrar la cantidad de modelos diferentes en la mesa de PC (es decir, los disponibles para la venta).
Para garantizar que solo se utilicen valores únicos al obtener indicadores estadísticos, cuando argumento de funciones agregadas puede ser usado parámetro DISTINTO. Otro parámetro TODOS es el valor predeterminado y supone que se cuentan todos los valores devueltos en la columna. Operador,
Si necesitamos obtener la cantidad de modelos de PC producidos todos fabricante, deberá utilizar Cláusula GRUPO POR, siguiendo sintácticamente DONDE cláusulas.
Cláusula GRUPO POR
Cláusula GRUPO POR Se utiliza para definir grupos de líneas de salida que se pueden aplicar a funciones agregadas (COUNT, MIN, MAX, AVG y SUM). Si falta esta cláusula y se utilizan funciones agregadas, entonces todas las columnas con nombres mencionados en SELECCIONAR, debe incluirse en Funciones agregadas, y estas funciones se aplicarán a todo el conjunto de filas que satisfagan el predicado de la consulta. De lo contrario, todas las columnas de la lista SELECT no incluido en funciones agregadas deben especificarse en la cláusula GROUP BY. Como resultado, todas las filas de la consulta de salida se dividen en grupos caracterizados por las mismas combinaciones de valores en estas columnas. Después de esto, se aplicarán funciones agregadas a cada grupo. Tenga en cuenta que para GROUP BY todos los valores NULL se tratan como iguales, es decir al agrupar por un campo que contiene valores NULL, todas esas filas caerán en un grupo.Si si hay una cláusula GROUP BY, en la cláusula SELECT sin funciones agregadas, entonces la consulta simplemente devolverá una fila de cada grupo. Esta característica, junto con la palabra clave DISTINCT, se puede utilizar para eliminar filas duplicadas en un conjunto de resultados.
Veamos un ejemplo sencillo:
| SELECCIONAR modelo, CONTAR(modelo) COMO Qty_model, AVG(precio) COMO Precio_promedio DESDE PC Agrupar por modelo; |
En esta solicitud, para cada modelo de PC se determina su número y costo promedio. Todas las filas con el mismo valor de modelo forman un grupo, y la salida de SELECT calcula la cantidad de valores y los valores de precio promedio para cada grupo. El resultado de la consulta será la siguiente tabla:
| modelo | Cant_modelo | Precio_promedio |
| 1121 | 3 | 850.0 |
| 1232 | 4 | 425.0 |
| 1233 | 3 | 843.33333333333337 |
| 1260 | 1 | 350.0 |
Si SELECT tuviera una columna de fecha, entonces sería posible calcular estos indicadores para cada fecha específica. Para hacer esto, debe agregar la fecha como una columna de agrupación, y luego se calcularían las funciones agregadas para cada combinación de valores (modelo-fecha).
Hay varios específicos reglas para realizar funciones agregadas:
- Si como resultado de la solicitud no se recibieron filas(o más de una fila para un grupo determinado), entonces no hay datos de origen para calcular ninguna de las funciones agregadas. En este caso, el resultado de las funciones COUNT será cero y el resultado de todas las demás funciones será NULL.
- Argumento función agregada no puede contener por sí mismo funciones agregadas(función de función). Aquellos. en una consulta es imposible, digamos, obtener el máximo de los valores medios.
- El resultado de ejecutar la función CONTAR es entero(ENTERO). Otras funciones agregadas heredan los tipos de datos de los valores que procesan.
- Si la función SUMA produce un resultado mayor que el valor máximo del tipo de datos utilizado, error.
Entonces, si la solicitud no contiene Cláusulas GROUP BY, Eso Funciones agregadas incluido en cláusula SELECCIONAR, se ejecutan en todas las filas de consulta resultantes. Si la solicitud contiene Cláusula GRUPO POR, cada conjunto de filas que tiene los mismos valores de una columna o grupo de columnas especificadas en Cláusula GRUPO POR, forma un grupo, y Funciones agregadas se realizan para cada grupo por separado.
TENER oferta
Si Dónde cláusula define un predicado para filtrar filas, luego TENER oferta aplica después de agrupar para definir un predicado similar que filtre grupos por valores Funciones agregadas. Esta cláusula es necesaria para validar los valores que se obtienen usando función agregada no de filas individuales de la fuente de registro definida en Cláusula DE, y de grupos de tales líneas. Por lo tanto, tal control no puede incluirse en Dónde cláusula.